
Abstract
Generative Artificial Intelligence (GenAI) systems are increasingly being deployed across diverse industries and research domains. Developers and end-users interact with these systems through the use of prompting and prompt engineering. Although prompt engineering is a widely adopted and extensively researched area, it suffers from conflicting terminology and a fragmented ontological understanding of what constitutes an effective prompt due to its relatively recent emergence. We establish a structured understanding of prompt engineering by assembling a taxonomy of prompting techniques and analyzing their applications. We present a detailed vocabulary of 33 vocabulary terms, a taxonomy of 58 LLM prompting techniques, and 40 techniques for other modalities. Additionally, we provide best practices and guidelines for prompt engineering, including advice for prompting state-of-the-art (SOTA) LLMs such as ChatGPT. We further present a meta-analysis of the entire literature on natural language prefix-prompting. As a culmination of these efforts, this paper presents the most comprehensive survey on prompt engineering to date.
The PRISMA Review Process
During paper collection, we followed a systematic review process grounded in the PRISMA method. We first scraped arXiv, Semantic Scholar, and ACL through a keyword search. Our keyword list was comprised of 44 terms, with each being closely related to prompting and prompt engineering. We then deduplicated our datset based on paper titles, conducted extensive human and AI review for relevance, and automatically removed unrelated papers by checking paper bodies for the term "prompt".

The PRISMA review process. We accumulate 4,247 unique records from which we extract 1,565 relevant records.
A Taxonomy of Prompting Techniques
We present a comprehensive taxonomy of prompting techniques, methods for instructing Large Language Models (LLMs) to complete tasks. We divide prompting techniques into three categories: text-based, multilingual, and multimodal. Multilingual techniques are used to prompt LLMs in non-English settings. Multimodal techniques are used when working with non-textual modalities such as image and audio.
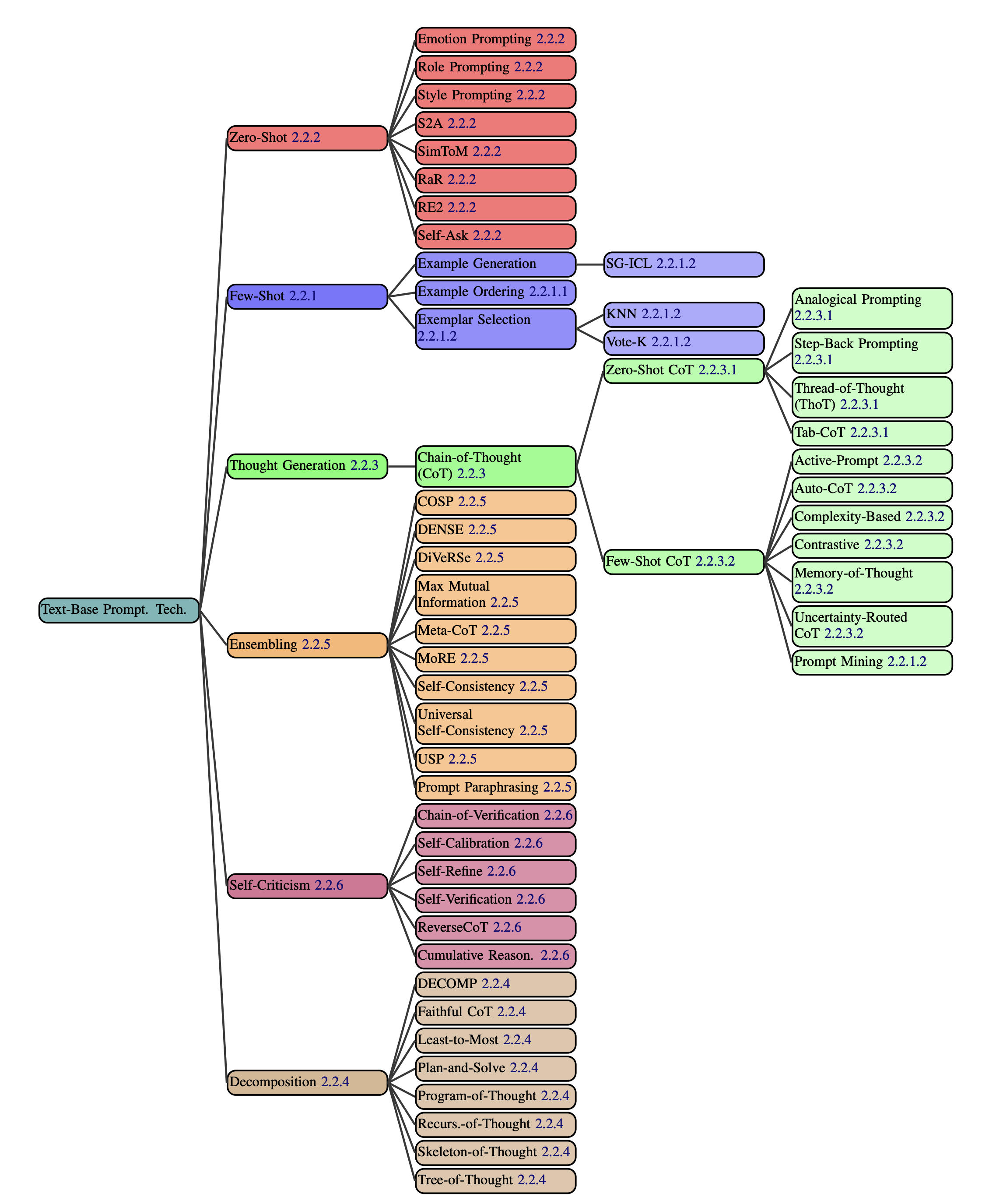
All text-based prompting techniques from our dataset.
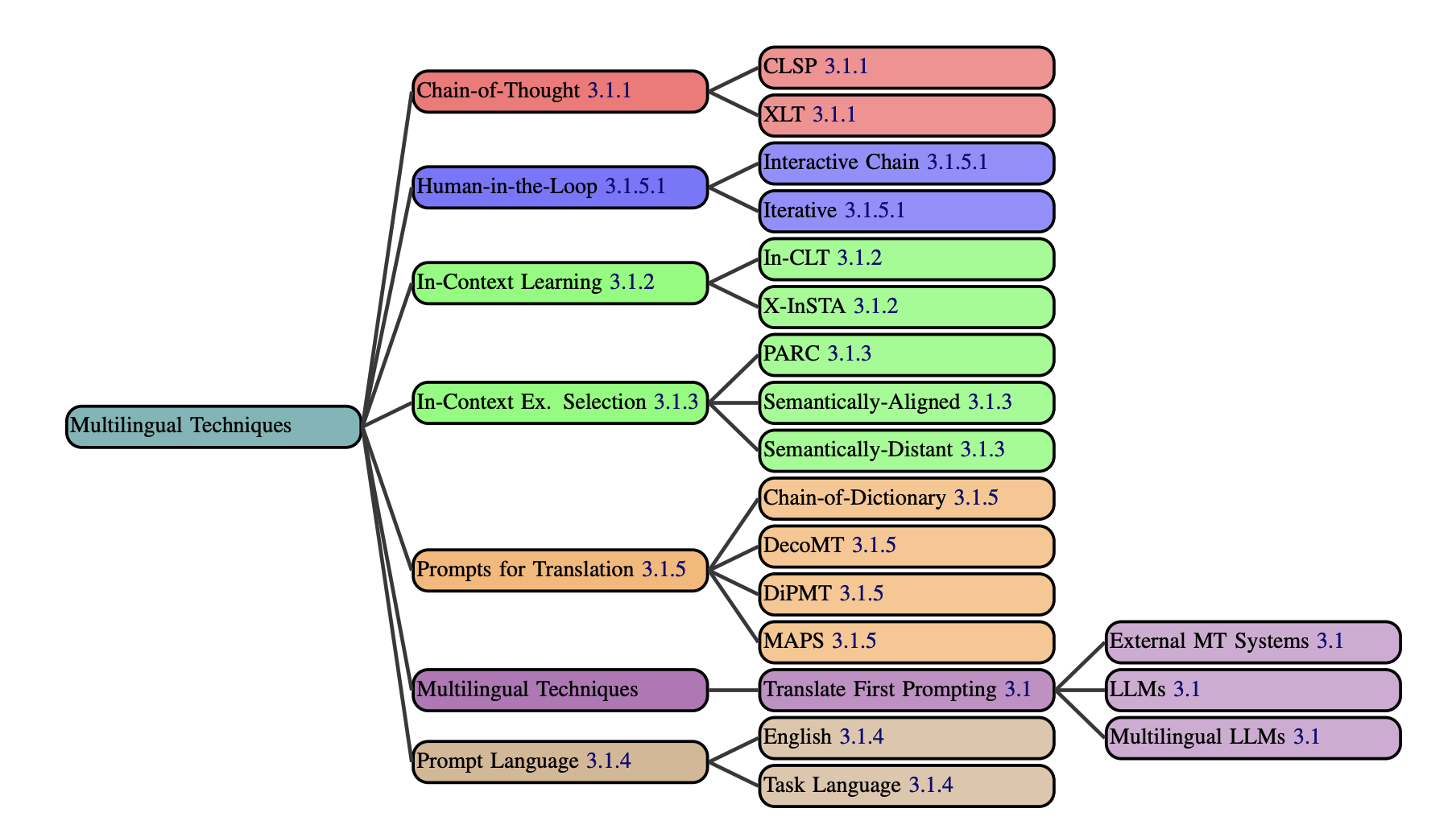
All multilingual prompting techniques.
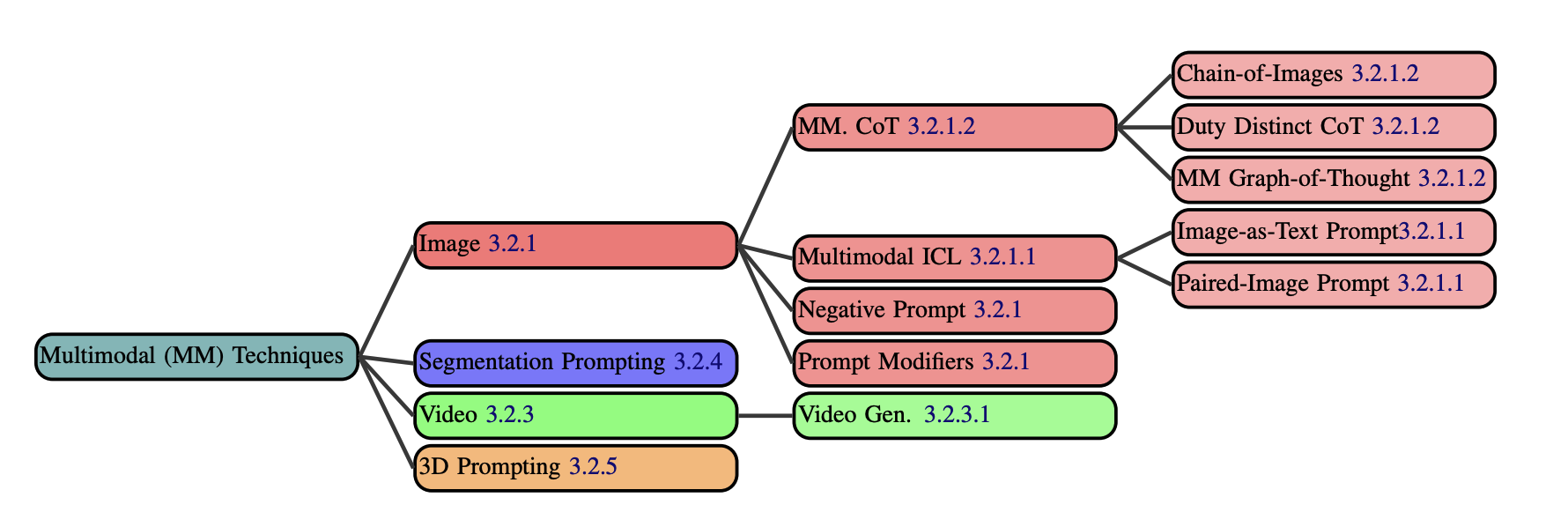
All multimodal prompting techniques.
Prompt Exploration and Advice
We discussed various prompting terms including prompt engineering, answer engineering, and few-shot prompting.



Case Study: MMLU Benchmarking
In our first case study, we benchmark six distinct prompting techniques using the MMLU benchmark. We also explore the impact of formatting on results, finding variations between two different formats for each prompting technique.

Accuracy values are shown for each prompting technique. Purple error bars illustrate the minimum and maximum for each technique, since they were each ran on different phrasings (except SC) and formats.
Case Study: Labelling for Suicide Crisis Syndrome (SCS)
In the second case study, we apply prompting techniques to the task of labelling reddit posts as indicative of suicide crisis syndrome (SCS). Through this case study, we aim to provide an example of the prompt engineering process in the context of a real world problem. We utilize the University of Maryland Reddit Suicidality Dataset and an expert prompt engineer, documenting the process in which they boost F1 score from 0 to 0.53.



The Prompt Report Dataset
Our systematic review of all prompting techniques is based on the dataset of 1,565 relevant papers we collected. Below is a preview of the dataset. Specific columns, such as 'abstract', have been excluded. The full dataset is available on Huggingface, including the complete CSV file and all paper PDFs.
We conducted several analyses of the dataset which can be found within the paper, including an analysis of citation counts for different GenAI models, prompting techniques, and datasets.



BibTeX
@misc{
schulhoff2024prompt,
title={The Prompt Report: A Systematic Survey of Prompting Techniques},
author={Sander Schulhoff and Michael Ilie and Nishant Balepur and Konstantine Kahadze and Amanda Liu and Chenglei Si and Yinheng Li and Aayush Gupta and HyoJung Han and Sevien Schulhoff and Pranav Sandeep Dulepet and Saurav Vidyadhara and Dayeon Ki and Sweta Agrawal and Chau Pham and Gerson Kroiz and Feileen Li and Hudson Tao and Ashay Srivastava and Hevander Da Costa and Saloni Gupta and Megan L. Rogers and Inna Goncearenco and Giuseppe Sarli and Igor Galynker and Denis Peskoff and Marine Carpuat and Jules White and Shyamal Anadkat and Alexander Hoyle and Philip Resnik},
year={2024},
eprint={2406.06608},
archivePrefix={arXiv},
primaryClass={cs.CL}
}